编辑中…
Requests
设置请求头headers
作用:在禁止爬取的网站中,通过反爬机制解决。设置headers信息,模拟成浏览器从而实现访问网站。
获取headers: 右键–>检查–>Network->Doc->html文件
需要按Fn+F5刷新出网页来
最常用的是user-agent和host
即按照图中显示操作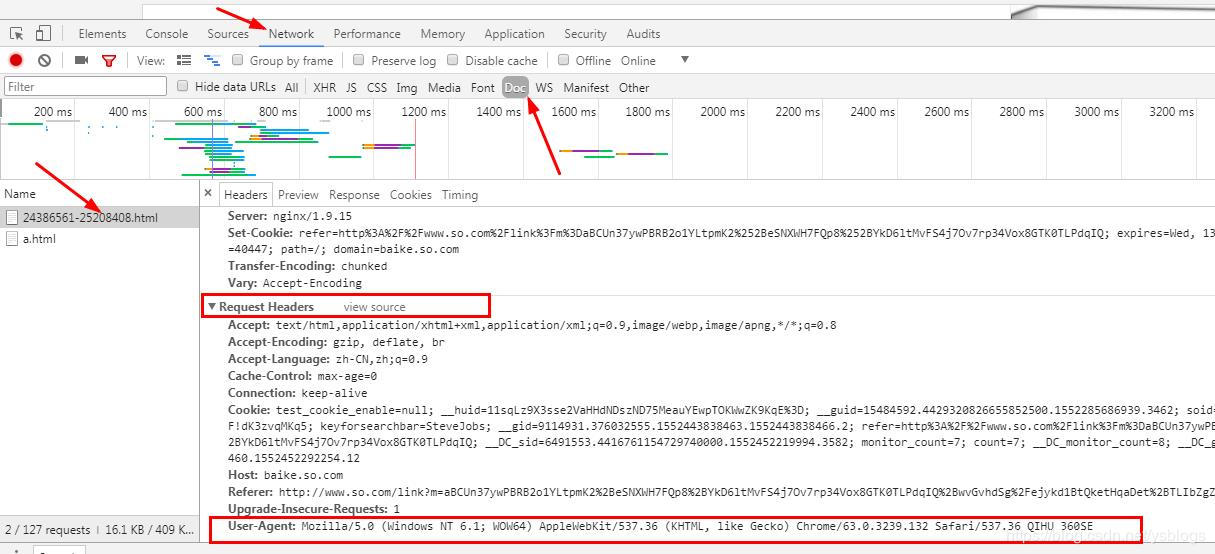
Posting Data
参考
Content-Type in Headers:
Form Data:
1 | POST |
JSON Payload
1 | POST |
Form Data
1 | import requests |
Notice that our response variable is a Response object. To be able to use this data, we need to apply a method or a property.
Text property - String
1 | result = response.text |
JSON Payload
1 | import requests |
By using the json.dumps method, we can convert the dictionary into a JSON-formatted string to post as a payload.
We used pprint to pretty-print our dictionary data.
Session
用于维持会话,跨请求时保持某些参数
文件读写
read
1 | f = open('/Users/michael/test.txt', 'r') |
python读到的内容转成str对象。
文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限。如果文件不存在,open()函数就会抛出一个IOError的错误,终止运行,不再调用f.close(),利用with语句解决这个问题。
1 | with open('/path/to/file', 'r') as f: |
等价于
1 | try: |
此外,调用read()会一次性读取文件的全部内容,如果文件过大,内存就爆了。保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。
write
1 | with open('/Users/michael/test.txt', 'w') as f: |
传入标识符w或者wb表示写文本文件或写二进制文件